


Why treat LLM inference as batched kernels to DRAM when a dataflow compiler can pipe tiles through on-chip FIFOs and stream converters?StreamTensor is a compiler that lowers PyTorch LLM graphs (GPT-2, Llama, Qwen, Gemma) into stream-scheduled dataflow accelerators on AMD’s Alveo U55C FPGA. The system introduces an iterative tensor (“itensor”) type to encode tile/order of streams, enabling provably correct inter-kernel streaming and automated insertion/sizing of DMA engines, FIFOs, and layout converters. On LLM decoding workloads, the research team reports up to 0.64× lower latency vs. GPUs and up to 1.99× higher energy efficiency.
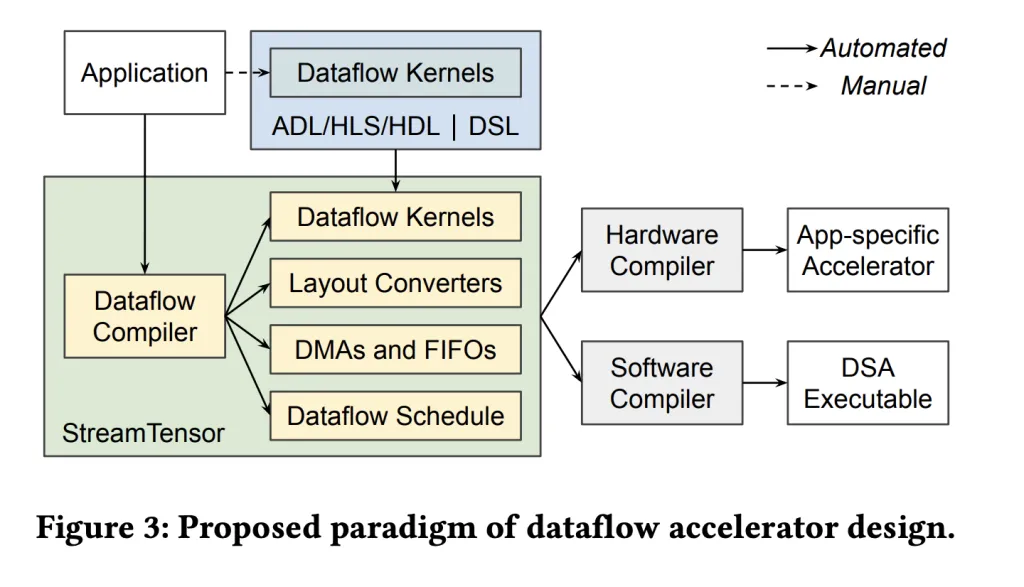
What StreamTensor does?
StreamTensor compiles PyTorch graphs into a stream-oriented dataflow design so that intermediate tiles are largely avoids off-chip DRAM round-trips via on-chip streaming and fusion; DMAs are inserted only when required; they are forwarded through on-chip FIFOs to downstream kernels. The compiler’s central abstraction—iterative tensors (itensors)—records iteration order, tiling, and layout, which makes inter-kernel stream compatibility explicit and drives converter generation only where needed. The framework also searches hierarchically over tiling, fusion, and resource allocation, and uses a linear program to size FIFOs to avoid stalls or deadlock while minimizing on-chip memory.
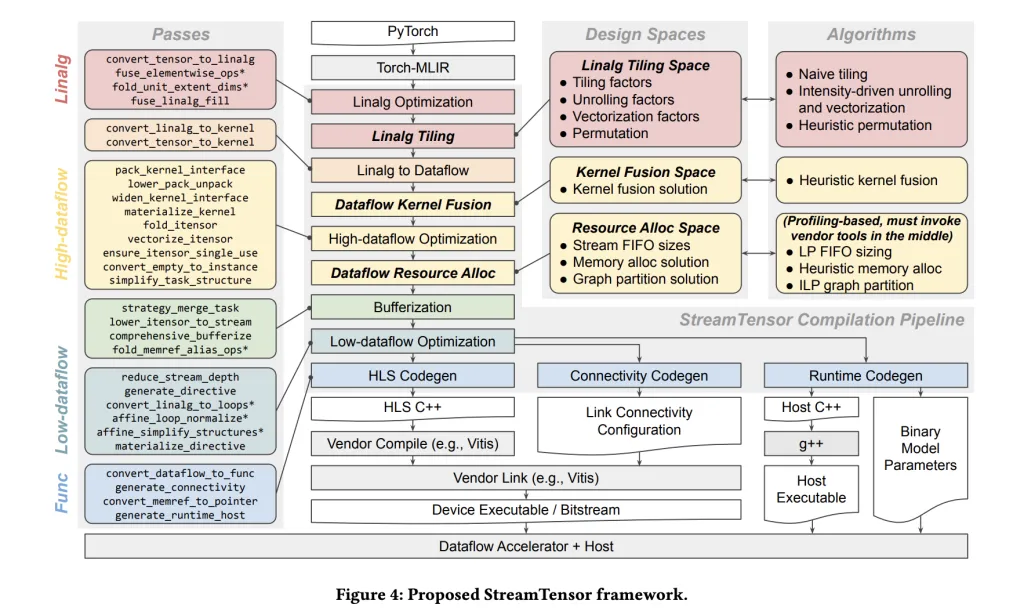
What’s actually new?
Hierarchical DSE. The compiler explores three design spaces—(i) tiling/unroll/vectorization/permutation at the Linalg level, (ii) fusion under memory/resource constraints, and (iii) resource allocation/stream widths—optimizing for sustained throughput under bandwidth limits.
End-to-end PyTorch → device flow. Models enter via Torch-MLIR, are transformed to MLIR Linalg, and then into a dataflow IR whose nodes become hardware kernels with explicit streams and host/runtime glue—no manual RTL assembly.

iterative tensor (itensor) typing system. A first-class tensor type expresses iteration order, tiling, and affine maps. This makes stream order explicit, allows safe kernel fusion, and lets the compiler synthesize minimal buffer/format converters when producers/consumers disagree.
Formal FIFO sizing. Inter-kernel buffering is solved with a linear-programming formulation to avoid stalls/deadlocks while minimizing on-chip memory usage (BRAM/URAM).
Results
Latency: up to 0.76× vs prior FPGA LLM accelerators and 0.64× vs a GPU baseline on GPT-2; Energy efficiency: up to 1.99× vs A100 on emerging LLMs (model-dependent). Platform context: Alveo U55C (HBM2 16 GB, 460 GB/s, PCIe Gen3×16 or dual Gen4×8, 2×QSFP28).
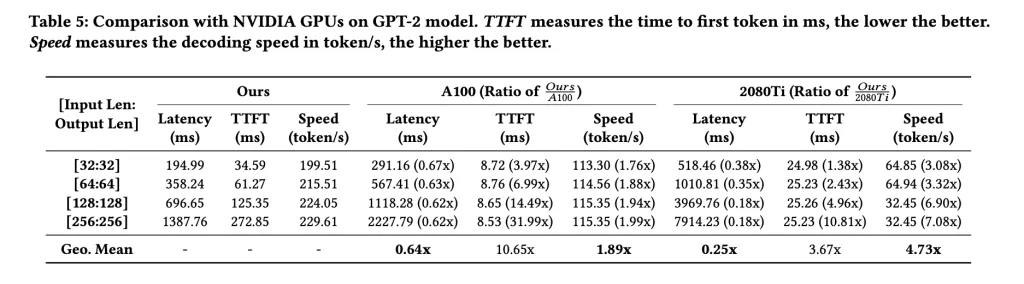
The useful contribution here is a PyTorch→Torch-MLIR→dataflow compiler that emits stream-scheduled kernels and a host/runtime for AMD’s Alveo U55C; the iterative tensor type plus linear-programming-based FIFO sizing enables safe inter-kernel streaming rather than DRAM round-trips. On reported LLM decoding benchmarks across GPT-2, Llama, Qwen, and Gemma, the research team show geometric-mean latency as low as 0.64× vs. a GPU baseline and energy efficiency up to 1.99×, with scope limited to decoding workloads. The hardware context is clear: Alveo U55C provides 16 GB HBM2 at 460 GB/s with dual QSFP28 and PCIe Gen3×16 or dual Gen4×8, which aligns with the streaming dataflow design.
Check out the Paper. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.

Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.

Be the first to comment